Trajectory Releases a Concurrent Multi-LoRA Training Stack for Continual Learning, Reporting a 2.81× Experiment-Throughput Gain
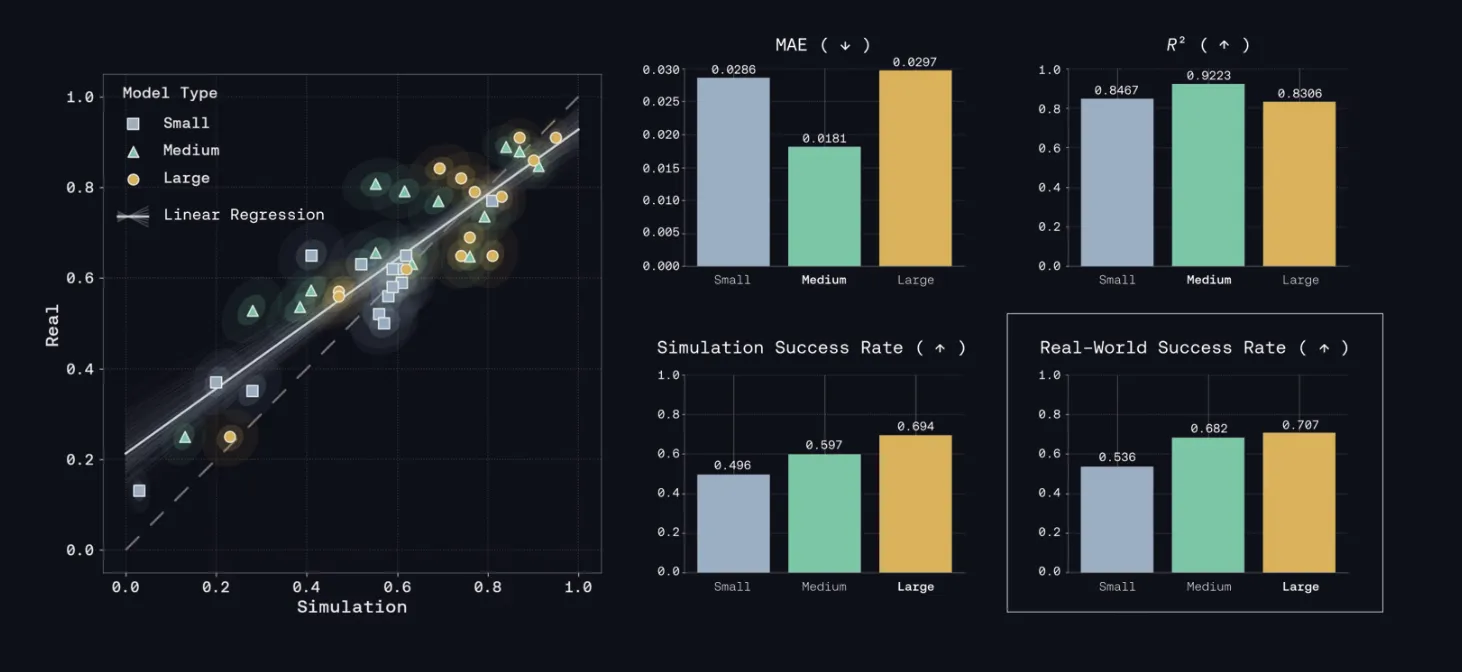
Trajectory's new multi-LoRA training stack achieves a 2.81x throughput increase for continual learning.
Developed with UC Berkeley Sky Lab and Anyscale, this stack maps individual RL experiments to dedicated LoRA adapters on a single hot engine. The approach, open-sourced as SkyRL, enables concurrent training without reward regression, significantly improving experiment throughput.



![Thumbnail for I built a tool to browse and plan CVPR workshop/tutorial days [P]](https://preview.redd.it/1yj8mkueph4h1.png?width=640&crop=smart&auto=webp&s=6e6b550e59ed4a4ee942c4c1020dc93d3e23b6d9)





![Thumbnail for How would you model this "strand" clustering problem? [P]](https://preview.redd.it/llqlupnwng4h1.png?width=140&height=69&auto=webp&s=6a4221ec8198b5cec6d3a06ce96ed8400f0814a8)