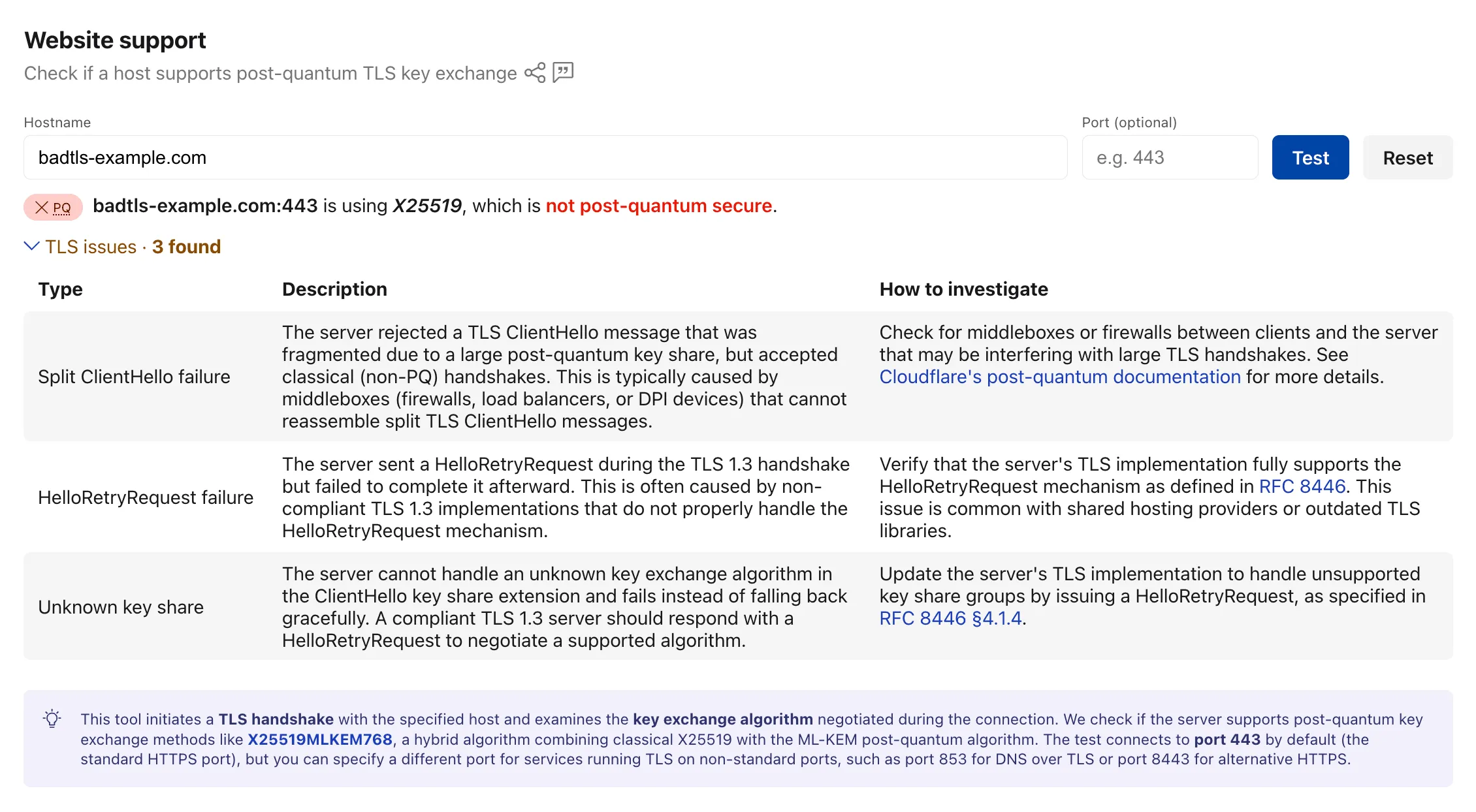
Mechanistic origins of catastrophic forgetting: why RL preserves circuits better than SFT?
New research explores why reinforcement learning (RL) preserves model circuits better than supervised fine-tuning (SFT) during training.
Researchers investigate the mechanistic differences between RL and SFT to explain why RL is more resistant to catastrophic forgetting. The study suggests that policy-gradient updates in RL maintain closer alignment with the base model's internal circuits compared to the weight shifts observed in SFT.