NVIDIA AI Releases Gated DeltaNet-2: A Linear Attention Layer That Decouples Erase and Write in the Delta Rule
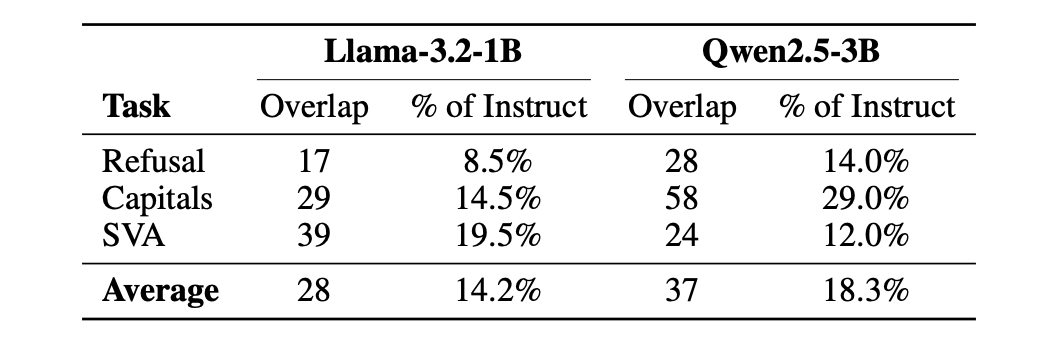
NVIDIA's Gated DeltaNet-2 improves linear attention by decoupling erase and write operations, outperforming Mamba-2 in efficiency and memory management.
Gated DeltaNet-2 addresses the memory bottleneck in linear attention models by using separate channel-wise gates for erasing old content and writing new data. This refinement allows for more precise updates to the fixed-size recurrent state, showing superior performance over previous architectures like Mamba-2 in tests trained on 100B tokens.




![Thumbnail for Per-pixel bounding-box regression + DBSCAN for handwritten word detection - visual walkthrough of WordDetectorNet [P]](https://preview.redd.it/qnfoh3sqjx2h1.png?width=140&height=94&auto=webp&s=e72cb3f3e061a1362a9bd5111d9e919341d48acb)







![Thumbnail for PapersWithCode new features - week 1 [P]](https://preview.redd.it/owlxn0b5u23h1.png?width=140&height=81&auto=webp&s=8407d85127cf40dd15ae91479ccd6b594dca1e37)